BlendMask: Top-Down Meets Bottom-Up for Instance Segmentation
Abstract
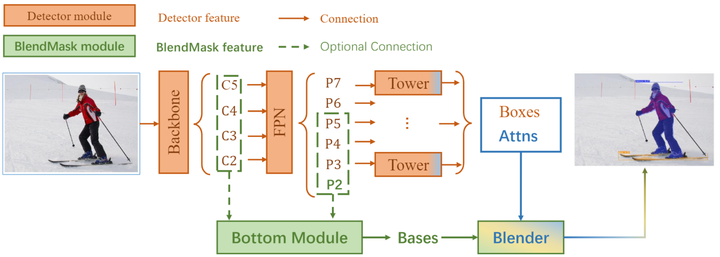
Contributed equally with the second author. In this work, we achieve improved mask prediction by effectively combining instance-level information with semantic information with lower-level fine-granularity. Our main contribution is a blender module which draws inspiration from both top-down and bottom-up instance segmentation approaches. The proposed BlendMask can effectively predict dense per-pixel position-sensitive instance features with very few channels, and learn attention maps for each instance with merely one convolution layer, thus being fast in inference. BlendMask can be easily incorporated with the state-of-the-art one-stage detection frameworks and outperforms Mask R-CNN under the same training schedule while being 20% faster.
Type
Publication
Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition